W większości przypadków, gdy trzeba zablokować dostęp SeekportBot lub inni crawl bots ze stroną internetową, powody są proste. Pająk sieciowy wykonuje zbyt wiele wejść w krótkim czasie i żąda zasobów serwera WWW lub pochodzi z wyszukiwarki, w której nie chcesz, aby Twoja witryna była indeksowana.
Jest to bardzo korzystne dla strony odwiedzanej przez okrawwpadłam na niego. Te pająki sieciowe są przeznaczone do eksploracji, przetwarzania i indeksowania zawartości stron internetowych w wyszukiwarkach. Google i Bing używają takich crawwpadłam na niego. Istnieją jednak również wyszukiwarki, które wykorzystują roboty do zbierania danych ze stron internetowych. Seekport jest jedną z tych wyszukiwarek, która używa crawSeekportBot ler do indeksowania stron internetowych. Niestety czasami wykorzystuje go nadmiernie i generuje niepotrzebny ruch.
Zawartość
Co to jest SeekportBot?
SeekportBot jest web crawler opracowany przez firmę Seekport, która ma siedzibę w Niemczech (ale korzysta z adresów IP z kilku krajów, w tym z Finlandii). Ten bot służy do przeszukiwania i indeksowania stron internetowych, aby mogły być wyświetlane w wynikach wyszukiwania. Seekport. Niefunkcjonalna wyszukiwarka, o ile wiem. Przynajmniej nie zwróciło mi to żadnych wyników dla żadnej frazy kluczowej.
SeekportBot zastosowania user agent:
"Mozilla/5.0 (compatible; SeekportBot; +https://bot.seekport.com)"Jak zablokować dostęp do SeekportBot lub innego crawKliknąłem na stronę internetową
Jeśli doszedłeś do wniosku, że ten czy inny pająk nie musi skanować całej witryny i robić niepotrzebnego ruchu na serwer WWW, masz kilka metod, za pomocą których możesz zablokować ich dostęp.
Firewall na poziomie serwera WWW
Są to aplikacje typu firewall open-source które można zainstalować w systemach operacyjnych Linux i może być skonfigurowany do blokowania ruchu na podstawie kilku kryteriów. Adres IP, lokalizacja, porty, protokoły lub agent użytkownika.
APF (Advanced Policy Firewall) to takie oprogramowanie, za pomocą którego można blokować niechciane boty na poziomie serwera.
Ponieważ SeekportBot i inne pająki sieciowe używają wielu bloków adresów IP, najskuteczniejsza reguła blokowania opiera się na „user agent". Tak więc, jeśli chcesz zablokować dostęp SeekportBot za pomocą APF, wszystko, co musisz zrobić, to połączyć się z serwerem WWW za pośrednictwem SSHi dodaj regułę filtrowania w pliku konfiguracyjnym.
1. Otwórz plik konfiguracyjny za pomocą nano (lub innego wydawcy).
sudo nano /etc/apf/conf.apf2. Poszukaj linii zaczynającej się od „IG_TCP_CPORTS” i dodaj agenta użytkownika, którego chcesz zablokować na końcu tego wiersza, a następnie przecinek. Na przykład, jeśli chcesz zablokować user agent "SeekportBot", linia powinna wyglądać tak:
IG_TCP_CPORTS="80,443,22" && IG_TCP_CPORTS="$IG_TCP_CPORTS,SeekportBot"3. Zapisz plik i zrestartuj usługę APF.
sudo systemctl restart apf.serviceDostęp "SeekportBot" zostanie zablokowany.
Filtr web crawls z pomocą Cloudflare – Zablokuj dostęp SeekportBot
Z pomocą Cloudflare wydaje mi się to najbezpieczniejszą i najwygodniejszą metodą, dzięki której można na różne sposoby ograniczyć dostęp niektórych botów do strony internetowej. Metoda, którą zastosowałem również w przypadku SeekportBot do filtrowania ruchu do sklepu internetowego.
Zakładając, że masz już witrynę dodaną do Cloudflare, a usługi DNS są aktywowane (czyli ruch do witryny przechodzi przez Cloudflare), wykonaj poniższe czynności:
1. Otwórz swoje konto Clouflare i przejdź do strony, do której chcesz ograniczyć dostęp.
2. Przejdź do: Security → WAF i dodaj nową regułę. Create rule.
3. Wybierz nazwę dla nowej reguły, Field: User Agent - Operator: Contains - Value: SeekportBot (lub inna nazwa bota) – Choose action: Block - Deploy.
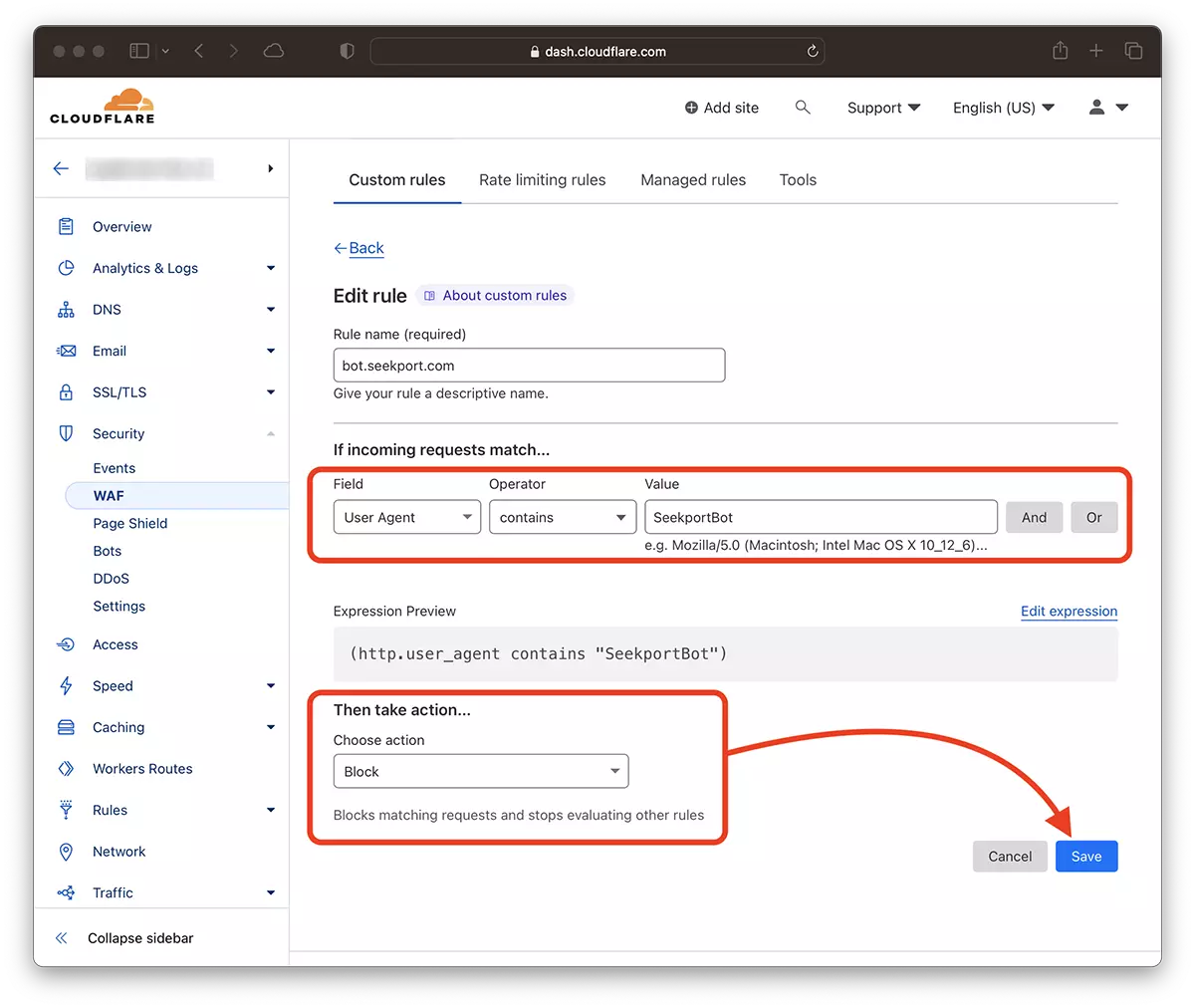
Już za kilka sekund nowa zasada WAF (Web Application Firewall) zaczyna działać.
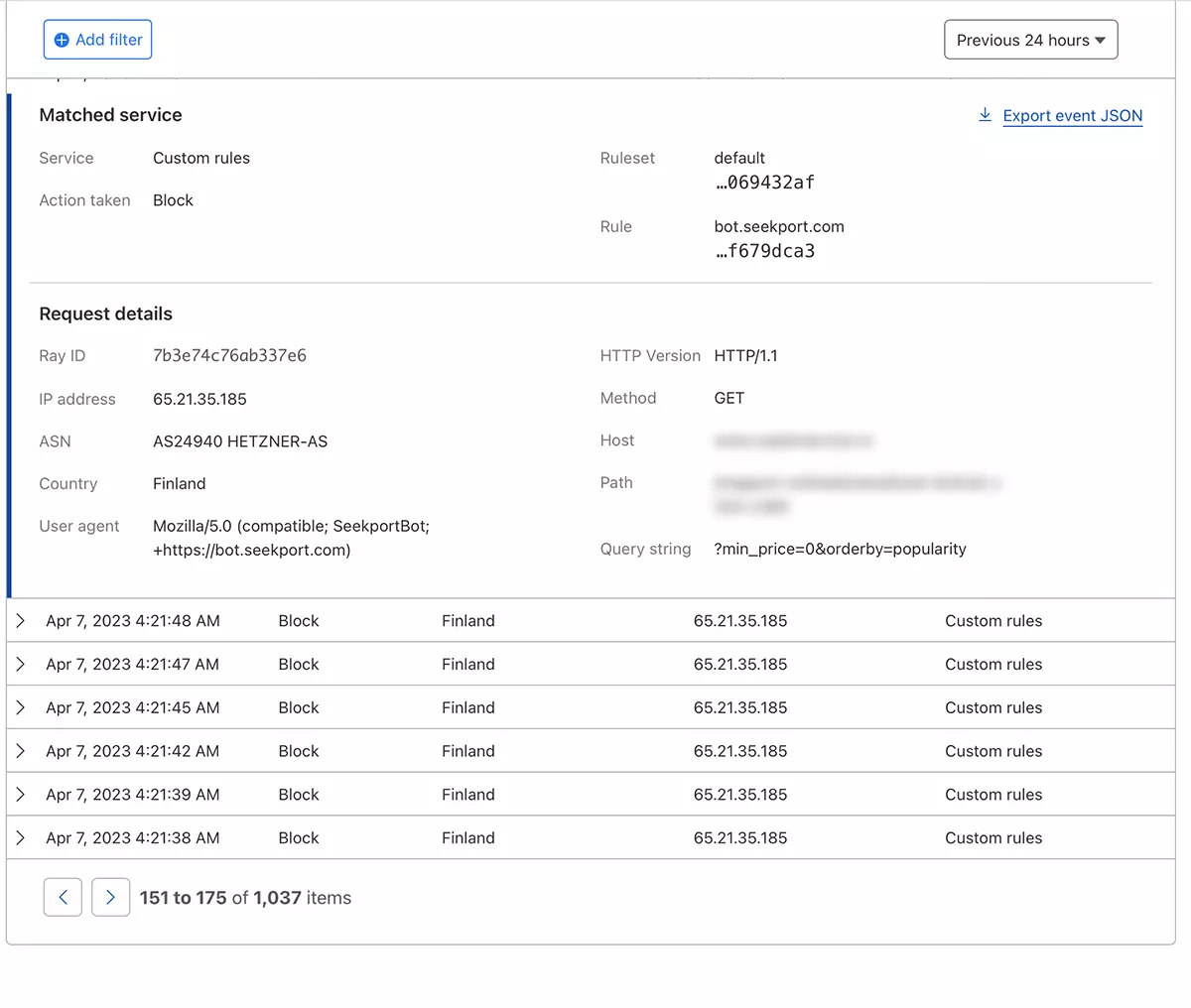
Teoretycznie można ustawić częstotliwość, z jaką pająk sieciowy uzyskuje dostęp do witryny robots.txt, ale... to tylko w teorii.
User-agent: SeekportBot
Crawl-delay: 4Wiele web crawlerii (z wyjątkiem Bing i Google) nie przestrzegają tych zasad.
Podsumowując, jeśli zidentyfikujesz plik web crawl który nadmiernie wchodzi na Twoją stronę, najlepiej całkowicie zablokować mu dostęp. Oczywiście, jeśli ten bot nie pochodzi z wyszukiwarki, w której chcesz być obecny.